
Research note: How can we pre-estimate sample size for multi-factorial ANOVA(ANCOVA) designed study?
Research Note: How can we pre-estimate sample size for multi-factorial ANOVA(ANCOVA) designed study?
Question:
Researchers, especially in the field of experimental psychology are still confused with how to estimate the required sample size of a complex design, for example, between-within mixed design ANOVA, or a more complicated one like, . By using which tool/packages could meet this demand does matter.
Thus, the aim of this note is to figure out the most proper(practical) way to estimate the required sample size of mixed design experimental study.
1. Background
We have to review how researcher estimate required sample size for a complex-design study first, and suggest the gap between theorized “power” and its application in research practice.
1.1 On power analysis
First of all, let us review the notion of power analysis. In most case, power of a binary hypothesis test is the probability that the test correctly rejects the null hypothesis when a specific alternative hypothesis is true (see table below).
| is True | is False | |
|---|---|---|
| Rejects | ||
| Rejects |
Here, we could also explain “power” with Signal Detection Theory. For example, regarding as the probability that one detected a signal even such signal did not appear ( is true), and such situation is also called as “false alert” (Type I error). In the line with this metaphor, we could also assume that could reflect the probability that one did not detected signal, although the signal did presented ( is False), similarly, such situation could be considered as a “miss” (Type II error). Considering the significance level as a global threshold of acceptance on the probability of Type I error, while as the threshold of accepting Type II error, could be captured as the capability of the system does not miss the signal. The notation I mentioned previously is also as known as Neyman-Pearson framework which could be very useful when we are choosing model in practice.
Since we are already familiar with understanding , and might have been trained during the practice in certain research as that when value is less than , the difference could be considered as significant. With the same line of capturing , another index to reflex the capability of “no miss” is excepted to be larger than . Cohen (1988) suggested a set of “pure” numbers, which are free of original measurement unit and could easily computed with collected data.
The simplest and well-known index might be Cohen’s ,
where, is the Effect size index for tests of means, and are population means expressed in raw and is the standard deviation of either population. The index reflect the aim of Cohen’s attempt on “pure” numeric scaled index with the actual explanation which could corresponded to probability of . Thus, we could also take a practical view on general notion of “power” as the ratio of “signal” and “noise” rather than a mathematical one.
It is worth noted that when a researcher is going to conduct power analysis, the definition of “power” should be assumed first. In the case of simple comparison between means of two groups, it could be reflected as the ratio of finite difference on total standard deviation. However, in the case of mixed designed ANOVA, although the general notion of “power” remains still, the power of main effect and interactions, the power on which measures differ on mathematical expressions. I will discuss this in the session 1.3.
1.2 How to compute required sample size
In most time, we could easily compute required sample size for simple situations like one sample, matched sample or two independent samples. For example, in the case of continuous dependent variable one sample test, effect size is defined as , to meet the threshold of significant level and power, required sample size are always given as the following:
where effect size is depended on which test researchers have chosen, for two independent samples and matched samples, effect size are and respectively. It is also notable that here refers to sample size per cell, if you are testing two independent samples, the final required sample size should be doubled.
Since all parameters, namely , and desired are determined in previous formula, we could even easily compute it without 3rd party packages in R or Python. Here I provide simple codes with R and we could also compare the result with popular package pwr and G*Power 3.1. Let us set significant level as 0.05, power as 0.8, effect size as 0.2, and calculate required sample size for one sample case test. Following code block shows that sample size is 197.
1 | calculateSampleSize <- function(effectSize, power, sigLevel) { |
Respectively, setting up Test family as “t tests”, Statistical test as “Means: Difference from constant (one sample case)” and Input parameters as same as code above. Total sample size was 199 and it was similar to the output of our simple R script with pwr.
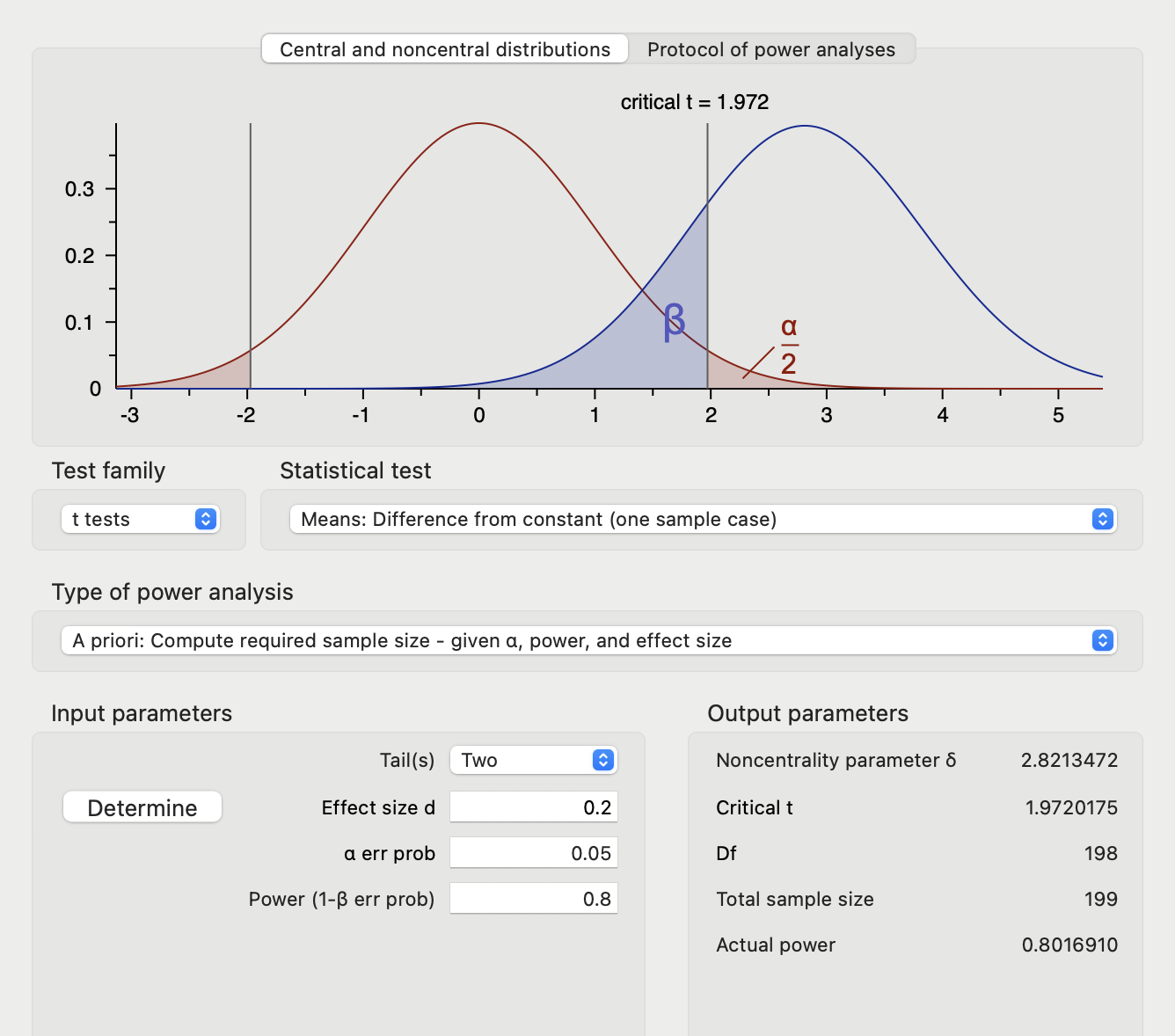
Although the conceptualization of effect size for ANOVA is similar with t-test, things become different due to a vary way when capturing “difference” mathematically. Even the origin inspiration of statistics testing could be described as finding which model fits the reality best, different definition or measurement of objects making it totally different.
1.3 Why estimating required sample on mixed-design study is confusing (annoying)?
Unlike test or test, mixed design studies usually involves ANOVA or GLM to test whether hypothesized model is significant first, and then test interested main effects or interaction in the lines with the hypothesis one by one. Thus, not only the calculation of effect size, but also “a priori” which estimate the required sample size always “floating” due to different interests.
First of all, let us review how ANOVA works, and figure out the “signal” and “noise”. As we all know, in one-way ANOVA (assuming we got levels with total sample size as ), we could use following formula (structural model) to describe and further provide the mathematical scaffold to test our hypothesis:
where, is the mean overall, is the effect of condition, is the error of each sample. We could demonstrate that, (representing the statistical traits of dependent variable) is captured as visible and concrete part , hypothesized effect of any categorical variable and error that could not be observed. Here, I would like to pass some assumptions (e.g., the unbiased inference on is ) on the traits of , just keep in mind that the core notion of ANOVA is using , and to reflect the uncertainty (or on the other hand, certainty) of , and . Considering we could only using limited sample to estimate , we have:
Since, each part of structural model comes from different view on how to categorize data. Those different blocking data view get different weights to explain the uncertainty of data. Thus, we have to average extent of explaining uncertainty of data within their own dimensions (degree of freedom). Like is ratio of difference on estimated population standard deviation, is also a ratio:
Now, what is “signal” and what is “noise”? According to Cohen (1988), the index that reflect the effect size should keep in the line with “free of measurement unit” and “express as averaged effect”, thus, as a generation to , effect size index for ANOVA is given by figuring out the ratio of uncertainty of measurement to uncertainty of error first, thus here comes index :
where, is the mean of the deviation of levels, as the following relationships between variances,
and keeping the conception of effect size as “ratio of the variance of specific measurement/manipulation to total variance”, we could now define as following:
with simple algebraic manipulation, we could got:
In summary, as same as the difference between (ratio of difference on total variance) and (ratio of difference on mean variance). In the case of ANOVA, compared to test statics (ratio of mean squares of manipulation to mean squares of error), could reflex proportion of total variance which is corresponded to the concept of effect size.
1.4 Mixed-design ANOVA with example: repeated measure ANOVA vs. ANCOVA ?
We have followed up with Cohen and summarized the indexing of effect size of one-way ANOVA so far. Finally, the problem showed up, how it comes to mixed-design ANOVA? We have extend more factors of design,
Example
Underlying same principle, we should add more items in a structural model. Let us take an example, assuming a researcher plans to collect data from a within-between designed study. There are three factors, two of them are between-subject, and one is repeated measurement (as a within-subject factor). A dummy data structure is as below.
| Subject | Condition | Gender | Measurement | Score |
|---|---|---|---|---|
| A | Manipulation | Male | Scale 1 | … |
| A | Manipulation | Male | Scale 2 | … |
| B | Manipulation | Female | Scale 1 | … |
| B | Manipulation | Female | Scale 2 | … |
| C | Control | Male | Scale 1 | … |
| C | Control | Male | Scale 2 | … |
| D | Control | Female | Scale 1 | … |
| D | Control | Female | Scale 2 | … |
| … | … | … | … | … |
In such case, we could give two structural models with mixed-design ANOVA and ANCOVA.
Structural model of repeated measures ANOVA
After researching across textbooks and articles, I found that researchers usually do not consider testing within-between interaction as critical. We could use following model to describe the experiment design:
where, and represent the main effects of Condition and Gender. For the repeated measurement is defined as , thus we could figure out that the total sample size is . Then, we could easily list F-value as following:
| Factor | Sum of Sq. | df. | Mean of Sq. | F |
|---|---|---|---|---|
Since we ignore the effect of Measurement, original design with between-within factors has changed into pure within-subjects designed one. However, if we do concern about within-between interaction in this example? According to Maxwell & Delaney (2004), a rough but useful approximation of the sample size needed is provided as following:
where is the number of within-subjects levels and is the correlation between measurements.
Structural model of ANCOVA
We could consider Scale 2 as target variable, and Scale 1 as a covariant:
or we could transfer formula as
1.5 Questions emerges: StackExchange
When exploring information about the correct usage of G*Power, I found following Question posted 2 years ago. A user of G*Power found inconsistency between the results of Repeated Measures ANOVA and ANCOVA underlying same clinical trials design (original link: https://stats.stackexchange.com/questions/535159/gpower-difference-in-sample-size-for-ancova-vs-repeated-measures-anova-in-clin).
The Inputs are as following:
1 | # ANCOVA |
The results were different, although noncentrality parameter , critical F and actual power were approximate, total sample size calculated by ANCOVA (128) was over 3 times than repeated measures ANOVA (34). Which one is correct?
Misunderstandings and misuses
The situation mentioned above is a common misunderstanding of using popular tool, namely G*Power to calculate the required sample size.
One step forward? Swift ANOVA power analysis question into Generalized Linear Model might help
Although the main stream of testing psychological effect now focusing on simple designed study, it is also necessary to make it clear with how to use power analysis tool to estimate the required sample size and evaluate the effect size with complex mixed-design studies.
Mixed model ANOVA or multi-variable ANCOVA could be regarded as equal to generalized linear model(GLM). Thus, the question I discussed above could also be solved alternatively by conducting the power analysis on GLM. However, this session might deviate from the core concern of this note, I would like to write another note for it.
2. Solutions:
Following solutions are recommended:
- use R package
pwrand correctly set up the params with error - use
G*Powerwithout misunderstanding the parameter settings
Steps by using pwr
Steps by using G*Power
In G*Power, estimating required sample of a study is called as “A priori” analysis, where sample size N is computed as a function of power level, significance level, and the to-be-detected population effect size.
Let us jump to the parts of F test and multi-regression.
3. Conclusion
In this note, I first viewed the idea of power analysis and how to calculate effect size and required sample size. Then I provided different ways to calculate required sample size for complex mixed-design study by using popular open access software or packages. Finally, for those 3 factorial mixed-design ANOVA, I suggested to transfer model into ANCOVA to calculate required sample size and for such multiple factorial ANOVA model over 4 factors, I suggested to regard them as general Gaussian linear model to calculate required sample size.
Keywords: #statistics #power_analysis #ANCOVA